Let’s optimize PostgreSQL Geospatial query performance!

One of the biggest challenges while querying geospatial data is performance and scalability. That could be faced with a geospatial area as big as a country, a continent, or as small as your garden.
The geometry datatype in a table can hold data in different forms, varying from a single point to a polygon with thousands of vertices. And of course, the bigger the object, the longer it will take to execute the query.
Here is how you can improve PostgreSQL Geospatial query performance with ST_Subdivide.
First, let’s take some sample data to create and identify a problem. Let’s pick up the ‘Countries dataset’ provided by Natural Earth and load the data into PostgreSQL/PostGIS table called countries.
Once you have loaded the data, execute the below SQL query to inspect the geometry data.
SELECT admin, ST_NPoints(area) AS points, ST_MemSize(area) AS size
FROM countries
ORDER BY points;ST_NPoints helps us count the number of vertices in geometry while ST_MemSize will help us compute the size-in-bytes of each geometry data.
With the above query, you will be able to see how different countries have thousands of vertices or points, for example, Canada has 68159 points with a size of 1 megabyte.
Considering that the default page size in the PostgreSQL database is 8kb, at least 149 countries in the table have geometry sizes larger than the page size, which is more than half.
Let’s execute a search query where we want to find a country where the given point lies.
SELECT * FROM countries
WHERE ST_Intersects('SRID=4326;POINT (46.6394 24.8280)', area);What’s the side effect? It requires more time to retrieve the data.
Although there are only 255 records in the countries table, it still requires several seconds to find a country with the provided Point, 18 seconds on my laptop. Imagine having a web service that calls for every geo point and the database alone takes 17-20 seconds to execute the query.
Why did that happen?
That is due to the large objects causing inefficient retrieval. A simpler explanation would be considering a country as big as China with large bounding boxes. This would result in indexes working inefficiently.
In addition to larger areas, the bigger objects come with a larger number of vertices, making the computation situation even worse for retrieval.
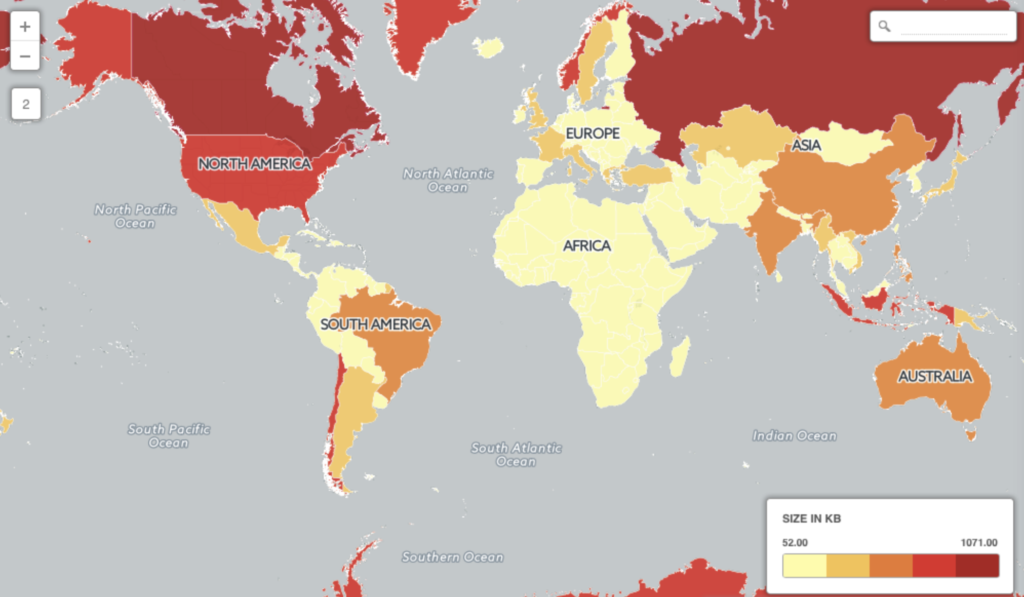
How to Improve PostgreSQL Geospatial query performance?
To improve the performance of this query, all you need to do is divide bigger polygons into smaller ones. You can do it easily by using the ST_Subdivide() function of PostGIS.
How does sub-dividing a polygon help? Well, the smaller the polygon, the smaller its memory size will be. Sub-dividing the polygons will reduce the polygon memory size even smaller than the database page size (remember 8kb?), which will result in improving the query performance.
Let’s have a look at it. Create a new table from the existing countries table.
CREATE TABLE countries_divided AS
SELECT ST_SubDivide(area) AS area
FROM countries;Here is a visual representation of how the table looks now
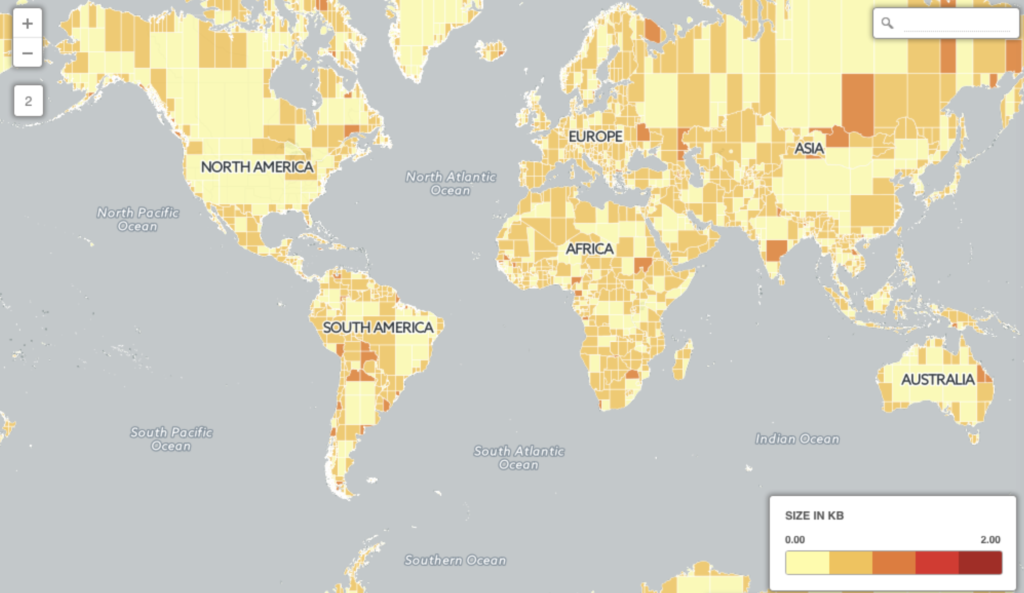
The same Canada, which had 68000+ vertices, is now divided into smaller polygons. The data stays the same, yet the only difference is each geometry data is subdivided into multiple (8633) rows i.e multiple polygons. Each of them has lesser than 255 vertices, which also means smaller than 4kb – way smaller than the database page size.
Now let’s retry the same geospatial query on the sub-divided polygons and see the difference.
SELECT * FROM countries_divided
WHERE ST_Intersects('SRID=4326;POINT (46.6394 24.8280)', area);On my same laptop, this query now takes 0.2 seconds to execute i.e. 200 milliseconds. Considering that the countries table had now been divided into multiple rows, the number of rows which was 255 previously is now increased to 8633. The query is now 90 times faster on a bigger table.
What did we achieve?
By sub-dividing the polygons, we have achieved two core things:
- The memory size of each polygon is now way too small as compared to the size of the original polygons. All the (sub-divided) polygons are smaller than the database page size.
- Since the polygons are smaller in size and cover smaller areas, the index searches are more likely to produce accurate results. That is because they will not be fetching the points that don’t lie in the polygon area.
This is just a log of the issue I faced and how ST_Subdivide helped me in improving the query.
If you have more ideas on improving the performance, please share your thoughts in the comments below.
Leave a Reply